Homework 4 (due April 19th 9pm)
Stat 154/254: Statistical Machine Learning
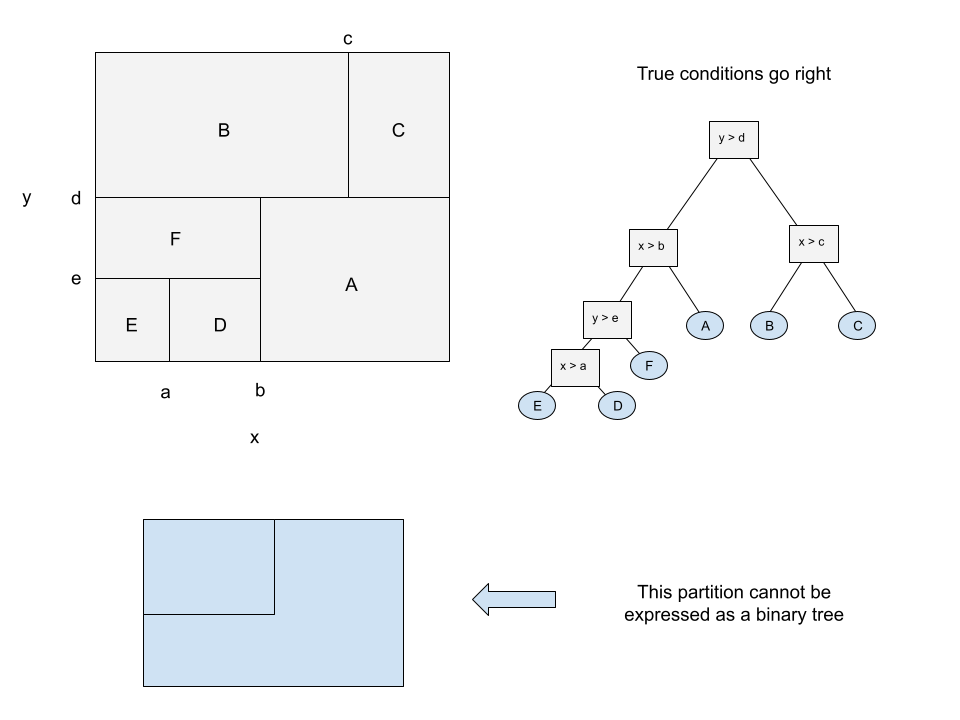
1 Draw your own partitions (based on Gareth et al. (2021) 8.4.1)
(a)
Draw an example of your own invention of a partition of a two–dimensional feature space that could result from a recurive binary splitting. Your example should contain at least six regions. Draw a decision tree corresponding to this partition. Be sure to label all aspects of your figures, including the regions, the cutpoints, and which region corresponds to which leaf of the tree.
(b)
Draw an example of your own invention of a partition of a two–dimensional feature space that could not result from a recurive binary splitting.
2 Aggregating bagged classifiers (based on Gareth et al. (2021) 8.4.5)
Suppose we fit classification trees to each of ten bootstrapped datasets containing regressors \(\boldsymbol{x}\) and red and green classes. For a particular observation \(\boldsymbol{x}_n\), each tree gives an estimate of \(p(\textrm{Red} \vert \boldsymbol{x}_n)\), which are:
0.1, 0.15, 0.2, 0.2, 0.55, 0.6, 0.6, 0.65, 0.7, and 0.75.
There are two way to combine these scores to make a single score:
- The majority vote
- Averaging the probabilities, and predicting red if and only if the average probability of red is \(>0.5\).
In this example, what is the final classification under these two approaches? Explain any discrepancy in intuitive terms; a single sentence is enough.
The classifiers are four green and six red, so the majority vote is red.
The average probability is 0.45, so the average probability approach chooses green.
The difference is due to the fact that though there are fewer green votes, their probability estimates are more extreme.
3 Trees as regression on partition indicators
Suppose \(\{A_1, \ldots, A_K\}\) is a partition of \(\mathbb{R}^{P}\), meaning \(A_k \bigcap A_j = \emptyset\) for \(k \ne j\). Let \(\boldsymbol{x}_n \in \mathbb{R}^{P}\), and let \(\boldsymbol{z}_{nk} = \mathrm{I}\left(\boldsymbol{x}_n \in A_k\right)\) denote the indicators of the sets \(A_k\), and \(\boldsymbol{z}_n = (\boldsymbol{z}_{n1}, \ldots, \boldsymbol{z}_{nK})^\intercal\). Finally, let \(\boldsymbol{Z}\) denote the \(N \times K\) matrix with \(\boldsymbol{z}_n^\intercal\) in row \(n\), and let \(\boldsymbol{Y}= (y_1, \ldots, y_N)\) denote a vector of real–valued responses.
Let \(N_k\) denote the number of \(\boldsymbol{x}_n\) in partition \(A_k\), and let \(\bar{y}_k\) denote the average of the responses \(y_n\) in \(A_k\): \(\bar{y}_k = \frac{1}{N_k} \sum_{n:\boldsymbol{x}_n \in A_k} y_n\).
(a)
Show that \(\boldsymbol{Z}^\intercal\boldsymbol{Z}\) is diagonal, with \(k\)–th diagonal entry equal to \(N_k\).
(b)
Let \(\hat{\boldsymbol{\beta}}\in \mathbb{R}^{K}\) denote the OLS coefficient from regressing \(\boldsymbol{Y}\sim \boldsymbol{Z}\boldsymbol{\beta}\). Show that \(\hat{\boldsymbol{\beta}}= (\bar{y}_1, \ldots, \bar{y}_K)^\intercal\).
(c)
Consider a regression tree topology \(T\) with leaves \(t\); write \(t\in T\) for the set of leaves, and write \(n \in t\) for the set of observations \(\boldsymbol{x}_n\) that end up in leaf \(t\). Given the tree \(T\), suppose we predict a constant \(c_t\) for observations \(\boldsymbol{x}\) that end up in leaf \(t\). Consider the problem of finding the optimal leaf predictions,
\[ (\hat{c}_1, \ldots, \hat{c}_{|T|}) = \underset{c_t \textrm{ for } t\in T}{\mathrm{argmin}}\, \sum_{t\in T} \sum_{n \in t} \left(y_n - c_t\right)^2. \]
Show directly that the optima are \(\hat{c}_k = \bar{y}_k\).
(d)
Show that your result in (c) also follows from (a) and (b). That is, show that the problem of finding the optimal predictions at the leaves of a regression tree is the same as the regression problem in part (b).
(d)
Consider the setting of (c), but for logistic loss. Suppose now that \(y_n \in \{0, 1\}\), and consider
\[ (\hat{c}_1, \ldots, \hat{c}_{|T|}) = \underset{c_t \textrm{ for } t\in T}{\mathrm{argmin}}\, \sum_{t\in T} \sum_{n \in t} \left(- y_n \log c_t- (1 - y_n) \log(1 - c_t) \right). \]
Show directly that the optima are \(\hat{c}_k = \hat{\pi}_k\), where now \(\hat{\pi}_k\) is the proportion of observations with \(y_n = 1\) in the leaf.
(a)
\(z_{nk} = 1\) if and only if \(\boldsymbol{x}_n \in A_k\), so \(\sum_{n=1}^Nz_{nk} = N_k\). And \(\sum_{n=1}^Nz_{nk}z_{nk'} = 0\) since each \(x_n\) can be in \(A_k\), in \(A_{k'}\), or in neither of them, but not in both, since the sets \(A_k\) are a partition. It follows that \(\boldsymbol{Z}^\intercal\boldsymbol{Z}\) has the stated form by writing out the matrix multiplication as sums.
(b)
The \(k\)–th entry of \(\boldsymbol{Z}^\intercal\boldsymbol{Y}\) is the sum of \(y_n\) among \(\boldsymbol{x}_n \in A_k\), and \((\boldsymbol{Z}^\intercal\boldsymbol{Z})^{-1}\) is diagonal with \(1/N_k\) on the diagonal by (a). The result follows from \(\hat{\boldsymbol{\beta}}= (\boldsymbol{Z}^\intercal\boldsymbol{Z})^{-1} \boldsymbol{Z}^\intercal\boldsymbol{Y}\).
(c)
Each leaf is an indpendent optimization problem, so
\[ \hat{c}_t= \underset{c_t}{\mathrm{argmin}}\, \sum_{n \in t} \left(y_n - c_t\right)^2, \]
which we know gives \(\hat{c}_k = \bar{y}_k\).
(d)
The tree defines a partition \(\boldsymbol{A}_t\), where \(\boldsymbol{x}_n \in \boldsymbol{A}_t\) if and only if \(\boldsymbol{x}_n \in t\) (that is, if \(\boldsymbol{x}_n\) ends up in leaf \(t\) according to the tree topology). In leaf \(t\) we predict \(c_t\), so our prediction for \(y_n\) is \(\sum_{t\in T} \boldsymbol{A}_t\c_t\), and the tree loss can be written equivalently as
\[ \sum_{t\in T} \sum_{n \in t} \left(y_n - c_t\right)^2 = \sum_{n=1}^N\left(y_n - \sum_{tin T} \boldsymbol{A}_tc_t\right)^2, \]
and the latter is the least squares problem from (a) and (b).
(d)
This can be done either by recognizing that this is logistic regression on indicators, or by observing again that
\[ \hat{c}_t= \underset{c_t}{\mathrm{argmin}}\, \sum_{n \in t} \left(- y_n \log c_t- (1 - y_n) \log(1 - c_t) \right). \]
The first order condition gives
\[ \begin{aligned} 0 ={}& \frac{-1}{\hat{c}_t}\sum_{n \in t} y_n + \frac{1}{1 - \hat{c}_t}\sum_{n \in t} (1 - y_n) \\ ={}& \frac{-1}{\hat{c}_t} N_t\hat{\pi}_t+ \frac{1}{1 - \hat{c}_t} N_t(1 - \hat{\pi}_t) \Rightarrow \\ 0 ={}& (1 - \hat{c}_t) \hat{\pi}_t- \hat{c}_t(1 - \hat{\pi}_t) \\={}& \hat{\pi}_t- \hat{c}_t, \end{aligned} \]
from which the result follows.
4 Interpretability of regression trees
A commonly claimed advantage of regression trees is their interpretability. That means it can be relatively easy to inspect why a regression tree made the prediction it did. But that does not mean that you can safely use trees to do variable selection for causal inference.
Suppose that you have data that’s generated according to the following process:
\[ \begin{aligned} z\sim{}& \mathcal{N}\left(0, 10\right)\\ x_1 \vert z\sim{}& \mathcal{N}\left(z, 0.1\right)\\ x_2 \vert z\sim{}& \mathcal{N}\left(z, 0.1\right)\\ y\vert z={}& \mathrm{I}\left(z> 0\right)\\ \end{aligned} \]
Suppose we don’t observe \(z\), but only observe a random set of \(N\) draws \((x_{n1}, x_{n2}, y_n)\) from this process.
(a)
Suppose we train a regression tree on this data using \(x_{n1}\) and \(x_{n2}\) as predictors. What is the probability that the variable \(x_1\) will be selected for the first split? (Hint: you can argue by symmetry without doing any calculations.)
(b)
Suppose you make the first split on \(x_{n1}\). Do you expect subsequent splits on \(x_{n2}\) to make large improvements in the fit? (You may argue intuitively, there is no need to do calculations.)
(c)
Suppose you have trained a tree in which \(x_{n1}\) is the most important variable, as measured by the average increase in fit within nodes that split on \(x_1\). Does this mean that \(x_{n2}\), taken alone, is a poor predictor of \(y\)? Does this mean that \(x_{n1}\) is causally related to \(y\)?
(a)
In the data generating process, the stochastic relationship between \(x_1\) and \(y\) is exactly the same as that between \(x_2\) and \(y\), so by symmetry the probability of choosing either as the first split is \(0.5\).
(b)
Since the variance of \(z\) is so much larger than the variance of \(x_1 | z\), \(x_1\) is nearly as good a predictor as \(z\) itself, and \(x_2\) can provide little extra information. Sometimes when \(z\) is very close to \(0\), it may be the case that you’d be better off predicting \(y=1\) if both \(x_1\) and \(x_2\) are positive, but this happens rarely. So you will get little predictive benefit from additionally splitting on \(x_2\).
(c)
As we’ve seen in (a) and (b), the fact that \(x_2\) adds little value once you’ve split on \(x_1\) does not mean that \(x_2\) is a poor predictor taken alone, nor does it mean that it is causally related. Like L1 regularization, if several explanatory variables are all equally powerful, trees will select one of them and then discard the rest.
5 Monotonic transformations (based on a problem from Erez Buchweitz)
Suppose we are finding the optimal split point for a node \(t\) using variable \(r_n\). For a split point \(\rho\), define
\[ \begin{aligned} \bar{y}_\rho^{-} :={}& \frac{\sum_{n \in t} \mathrm{I}\left(r_n < \rho\right) y_n}{\sum_{n \in t} \mathrm{I}\left(r_n < \rho\right)} \\ \bar{y}_\rho^{+} :={}& \frac{\sum_{n \in t} \mathrm{I}\left(r_n > \rho\right) y_n}{\sum_{n \in t} \mathrm{I}\left(r_n > \rho\right)} \\ R(\rho) ={}& \sum_{n \in t} \left( (y_n - \bar{y}_\rho^{-})^2 \mathrm{I}\left(r_n < \rho\right) + (y_n - \bar{y}_\rho^{+})^2 \mathrm{I}\left(r_n > \rho\right) \right). \end{aligned} \]
Typically there are a set of \(\rho\) that all produce the same value of \(R(\rho)\) lying between two datapoints \(r_{-}\) and \(r_{+}\). Suppose that, when this happens, we always take our split point to be the average, \(\hat\rho = \frac{1}{2}(r_{+} + r_{-})\)
Consider applying CART with the above splitting procedure to regression observations of \((\boldsymbol{x}_n, y_n)\), and on \((\boldsymbol{z}_n, y_n)\), where each component of \(\boldsymbol{z}_n\) is a monotonic transformation of the corresponding component of \(\boldsymbol{x}_n\). That is, \(\boldsymbol{z}_{np} = \phi_p(\boldsymbol{x}_{np})\), for each \(p\), where \(\phi_p\) is either strictly increasing or strictly decreasing.
(a)
In general, will the training error be different for the two datasets? Why or why not?
(b)
In general, will the test error be different for the two datasets? Why or why not?
(c)
Construct a simple one–dimensional example in which one transformation gives a good test set error and the other does not.
(a)
The training error will be identical. Since the transformation is either strictly increasing or decreasing, it does not change the sorting of the regressors in any leaf, and so the optimal split points will occur between the same pairs of points, irrespective of whether we split on \(\boldsymbol{x}\) or \(\boldsymbol{z}\). That is, if we split between \(\boldsymbol{x}_{np}\) and \(\boldsymbol{x}_{np'}\) at leaf \(t\), we will split between on \(\boldsymbol{z}_{np}\) and \(\boldsymbol{z}_{np'}\) at the same leaf.
(b)
As long as \(\phi\) is non-linear, the test error may be different in general because the actual split points will be different, despite the splits being between the same pairs of datapoints. This is because averages in one space are not the same as averages in the other. Formally, you might say that:
\[ \frac{1}{2} (\boldsymbol{x}_{np} + \boldsymbol{x}_{np'}) = \frac{1}{2} (\phi^{-1}(\phi(\boldsymbol{x}_{np})) + \phi^{-1}(\phi(\boldsymbol{x}_{np'}))) = \frac{1}{2} (\phi^{-1}(\boldsymbol{z}_{np}) + \phi^{-1}(\boldsymbol{z}_{np'})) \ne \phi^{-1}\left( \frac{1}{2} (\boldsymbol{z}_{np} + \boldsymbol{z}_{np'})\right). \]
(c)
Suppose that we have two points, \(x_1 = -10\) and \(x_2 = 10\), and \(y= \mathrm{I}\left(x> 0\right)\). A classifier on \(x\) splits at \(\frac{1}{2}(-10 + 10) = 0\) which is the optimal point. But if we take \(z= \exp(x)\), which is strictly increasing, then we split at \(\frac{1}{2}(\exp(-10) + \exp(10)) \approx 11013\), which corresponds to \(x= \log (11013) = 9.3\), a terrible split point.
\[ \]
6 The accuracy of bagging (based on Bühlmann and Yu (2002)) (254 only \(\star\) \(\star\) \(\star\))
In this problem we explore some simple settings in which bagging does and does not work.
(a)
Suppose we observe \(\boldsymbol{Y}= (y_1,\ldots,y_N)^\intercal\), which we use to fit the constant model, \(f= \beta_0\). We use least squares regression, so \(\hat{\beta}_0 = \frac{1}{N} \sum_{n=1}^Ny_n\), and so \(\hat{f}= \frac{1}{N} \sum_{n=1}^Ny_n\).
Let \(\boldsymbol{Y}^* = (y_1^*, \ldots, y_N^*)^\intercal\) denote a bootstrap sample from \(\boldsymbol{Y}\), and write the ideal bagging estimator as
\[ \hat{f}^* = \mathbb{E}_{\boldsymbol{Y}^*}\left[\frac{1}{N} \sum_{n=1}^Ny_n^*\right]. \]
Show that \(\hat{f}^* = \hat{f}\). That is, bagging does not improve the estimator in this case. In fact, it makes it worse if \(\hat{f}^*\) is estimated using a finite number of bootstrap samples, since it increases the variance due to the bootstrap Monte Carlo sampling.
(b)
Next, suppose that we observe pairs \((x_n, y_n)\), where \(x_n \sim \mathcal{N}\left(\mu, 1\right)\) and \(y_n \in \{0,1\}\). Writing \(\boldsymbol{X}\) for the vectors of observations, suppose that we wish to predict \(y_n\) from \(x_n\) using the following classifier:
\[ \hat{f}(x; \boldsymbol{X}) = \mathrm{I}\left(x\ge \frac{1}{N} \sum_{n=1}^Nx_n\right). \]
Let \(\Phi(\cdot)\) denote the CDF of the standard normal distribution. Show that, for a fixed \(x\),
\[ \begin{aligned} \mathbb{E}_{\boldsymbol{X}}\left[\hat{f}(x; \boldsymbol{X})\right] ={}& \Phi(\sqrt{N}(x- \mu)) \\ \mathrm{Var}_{\boldsymbol{X}}\left(\hat{f}(x; \boldsymbol{X})\right) ={}& \Phi(\sqrt{N}(x- \mu))(1 - \Phi(\sqrt{N}(x- \mu))). \end{aligned} \]
(c)
In the setting of (b), let \(\boldsymbol{X}^*\) denote a bootstrap sample from \(\boldsymbol{X}\).
Let \(\bar{x}= \frac{1}{N} \sum_{n=1}^Nx_n\). Using this, show that the bagged estimator for a fixed \(x\) and large \(N\) is
\[ \begin{aligned} \hat{f}^*(x; \boldsymbol{X}) \approx{}& \Phi(\sqrt{N}(x- \bar{x})). \end{aligned} \]
Note that the bagged estimator replaced a sharp threshold \(\hat{f}(x; \boldsymbol{X}) = \mathrm{I}\left(x\ge \bar{x}\right)\) with a soft threshold \(\hat{f}^*(x; \boldsymbol{X}) \approx \Phi(\sqrt{N}(x- \bar{x}))\).
Hint: Under the bootstrap distribution, you may use without proof the fact that, for large \(N\), \(\sqrt{N}(\frac{1}{N} \sum_{n=1}^Nx_n^* - \bar{x}) \approx \mathcal{N}\left(0,1\right)\) under the bootstrap randomness. (Note that in the bootstrap sampling distribution, \(\bar{x}\) is fixed.)
(d)
Evaluating the result for (b) and (c) at \(x= \mu\), show that, for large \(N\),
\[ \begin{aligned} \mathbb{E}_{\boldsymbol{X}}\left[\hat{f}^*(x; \boldsymbol{X})\right] \approx{}& \frac{1}{2} & \mathbb{E}_{\boldsymbol{X}}\left[\hat{f}(x; \boldsymbol{X})\right] ={}& \frac{1}{2} \\ \mathrm{Var}_{\boldsymbol{X}}\left(\hat{f}^*(x; \boldsymbol{X})\right) \approx{}& \frac{1}{12} & \mathrm{Var}_{\boldsymbol{X}}\left(\hat{f}(x; \boldsymbol{X})\right) ={}& \frac{1}{4}. \end{aligned} \]
Conclude that, for \(x= \mu\), the bagged estimator maintains the same expected prediction function, but reduces the variance by a factor of \(3\).
Hint: use the fact that \(\sqrt{N}(\mu - \bar{x})\) is a standard normal, and that \(\Phi(Z)\) is uniform if \(Z\sim\mathcal{N}\left(0,1\right)\).
(a)
This was done in lecture.
(b)
By normality, \(\frac{1}{N} \sum_{n=1}^Nx_n \sim \mathcal{N}\left(\mu, N^{-1}\right)\), so \(\sqrt{N}\left(\frac{1}{N} \sum_{n=1}^Nx_n - \mu \right) \sim \mathcal{N}\left(0, 1\right)\). Let \(z\sim \mathcal{N}\left(0,1\right)\). Then
\[ \begin{aligned} \mathbb{E}_{\boldsymbol{X}}\left[\hat{f}(x; \boldsymbol{X})\right] ={}& \mathbb{P}_{\,}\left(x\ge \frac{1}{N} \sum_{n=1}^Nx_n\right) \\={}& \mathbb{P}_{\,}\left(\sqrt{N}(x- \mu) \ge z\right) \\={}& \Phi(\sqrt{N}(x- \mu)). \end{aligned} \]
Since \(\mathrm{I}\left(x\ge \frac{1}{N} \sum_{n=1}^Nx_n\right)\) is a binary variable, with expectation \(p = \Phi(\sqrt{N}(x- \mu))\), its variance is \(p(1 - p)\), and plugging in gives the desired answer.
(c)
The reasoning is as in (b) but using the CLT applied to the bootstrap distribution.
\[ \begin{aligned} \hat{f}^*(x; \boldsymbol{X}) ={}& \mathbb{E}_{\boldsymbol{X}^*}\left[\hat{f}^*(x; \boldsymbol{X}^*)\right] \\={}& \mathbb{E}_{\boldsymbol{X}^*}\left[\mathrm{I}\left(x\ge \frac{1}{N} \sum_{n=1}^Nx^*_n\right)\right] \\={}& \mathbb{E}_{\boldsymbol{X}^*}\left[\mathrm{I}\left(\sqrt{N}(x- \bar{x}) \ge \sqrt{N}(\frac{1}{N} \sum_{n=1}^Nx^*_n - \bar{x})\right)\right] \\\approx{}& \mathbb{E}_{\boldsymbol{X}^*}\left[\mathrm{I}\left(\sqrt{N}(x- \bar{x}) \ge Z\right)\right] \\=& \Phi(\sqrt{N}(x- \bar{x})). \end{aligned} \]
(d)
Evaluating the result for (b) and (c) at \(x= \mu\), show that
\[ \begin{aligned} \mathbb{E}_{\boldsymbol{X}}\left[\hat{f}^*(x; \boldsymbol{X})\right] ={}& \mathbb{E}_{\boldsymbol{X}}\left[\Phi(\sqrt{N}(\mu - \bar{x}))\right] \\={}& \mathbb{E}_{\boldsymbol{X}}\left[\Phi(Z)\right] \\={}& \int_0^1 u du \\={}& \frac{1}{2}. \end{aligned} \]
and
\[ \begin{aligned} \mathrm{Var}_{\boldsymbol{X}}\left(\hat{f}^*(x; \boldsymbol{X})\right) ={}& \int_0^1 u^2 du - \frac{1}{4} \\={}& \frac{1}{3} - \frac{1}{4} \\={}& \frac{1}{12}. \end{aligned} \]
7 Trees as approximations to linear functions (254 only \(\star\) \(\star\) \(\star\))
Suppose you are trying to use a regression tree to represent the function \(y= \mathbb{E}_{\,}\left[y\vert x\right] := f(x) = x\) for \(x\in \mathbb{R}^{}\). That is, \(y\) is observed without noise and the regression function is linear, but we’re approximating the linear function with a decision tree. Assume that \(x\) is uniformly distributed on \([0,1]\).
(a)
Consider a connected set \(A\) with endpoints \(A_{L}\) and \(A_{R}\) (i.e. \(A = \{ x: A_{L} \le \boldsymbol{X}< A_{R} \}\)), and let \(\Delta = A_{R} - A_{L}\) denote the width of \(A\).
Suppose we predict \(y^{*}_A\) for \(x\in A\), where \(y^{*}_A = \underset{c}{\mathrm{argmin}}\, \int_{A} (f(x) - c)^2 dx\) is the ideal least squares estimator in the set \(A\). Show that \(y^{*}_A = \frac{1}{2} (A_{L} + A_{R})\), and that the integrated error is
\[ \int_{A} (f(x) - y^{*}_A)^2 dx = \frac{\Delta^3}{12}. \]
(b)
Suppose we partition the unit interval into \(K\) equally spaced intervals, each with width \(1/K\), with indicator functions \(A_k\). Suppose we find the optimal least–squares prediction \(y^{*}(x)\) for the regression of \(y\) on these indicators. Using (a), find an expression for the expected squared error \(\mathbb{E}_{x,y}\left[(y- y^{*}(x))^2\right]\) as a function of \(K\).
(c)
In the setting of (b), for a fixed \(\varepsilon > 0\), how large do we need to make \(K\) in order to acheive \(\mathbb{E}_{x,y}\left[(y- y^{*}(x))^2\right] \le \varepsilon\)?
(d)
Suppose we grow a regression tree with depth \(D\), where each branch is split at the optimal point in the middle of the parent’s interval. For a fixed \(\varepsilon > 0\), how large do we need to make \(D\) in order to acheive \(\mathbb{E}_{x,y}\left[(y- y^{*}(x))^2\right] \le \varepsilon\)?
Note: It seems to me that computer scientists love to do accuracy order calculations like this!
(a)
All we really need is the two integrals
\[ \begin{aligned} \int_{a}^b x dx ={}& \frac{1}{2}\left[ x^2 \right]_a^b = \frac{1}{2}(b^2 - a^2) \textrm{ and}\\ \int_{a}^b x^2 dx ={}& \frac{1}{3}\left[ x^3 \right]_a^b = \frac{1}{3}(b^3 - a^3). \end{aligned} \]
We know that \(y^{*}_A\) satisfies the first–order condition
\[ \frac{\partial}{\partial c} \int_A (f(x) - c)^2 dx = -2 \int_A (f(x) - c) dx =0 \]
so \[ \begin{aligned} y^{*}_A ={}& \frac{\int_A f(x) dx}{\int_A dx} \\={}& \frac{\frac{1}{2}(A_R^2 - A_L^2)}{A_R - A_L} \\={}& \frac{1}{2}(A_R + A_L). \end{aligned} \]
A simple way to do the second integral is to note that \(\int_0^1 (x- 1/2)^2 dx = \frac{1}{12}\), so that \(\int_0^1 (\Delta x- A_L - (\Delta/2 + A_L))^2 dx = \frac{\Delta^2}{12}\). Making the subsititution \(z= \Delta x- A_L\) into the integral gives the desired result.
(b)
\[ \begin{aligned} \mathbb{E}_{x,y}\left[(y- y^{*}(x))^2\right] ={}& \mathbb{E}_{x}\left[\sum_{k=1}^K \mathrm{I}\left(\frac{k-1}{K} < x< \frac{k}{K}\right) (x- y^{*}(x))^2\right] \\={}& \sum_{k=1}^K \int_{(k-1)/K}^{k/K} \left(x- y^{*}_k \right)^2 dx\\={}& K \frac{1}{12 K^3}\\={}& \frac{1}{12 K^2}, \end{aligned} \]
where we used (a) in the second-to-last line.
(c)
By (b) we require
\[ \frac{1}{12 K^2} \le \varepsilon \quad\Leftrightarrow\quad K \ge \frac{1}{\sqrt{12 \varepsilon}}. \]
Since \(K\) must be an integer, we can take \(K = \lceil \frac{1}{\sqrt{12 \varepsilon}} \rceil\).
(d)
The optimal split point is always in the middle of the interval, so if we have a tree of depth \(D\) then we have a partition into \(K = 2^{D}\) regions. (Here I take a depth one tree to be a single split, but the question is ambiguous, and taking a depth one tree to be a single node is also fine, in which case you get \(K=2^{D-1}\).)
By (c) we then require
\[ 2^D = \exp(D \log(2)) \ge \frac{1}{\sqrt{12 \varepsilon}} \quad\Leftrightarrow\quad D \ge \frac{\log(-12 \varepsilon)}{\log(2)}. \]
Again, \(D\) must be an integer, so we can take \(D = \lceil \frac{\log(-12 \varepsilon)}{\log(2)} \rceil\).